Dirección de la oficina
Sevilla, España
Sevilla, España
Número de teléfono
+(34) 624 816 969
Sevilla, España
Sevilla, España
+(34) 624 816 969






 by ForgeNEX
by ForgeNEX La capacidad de ejecutar modelos de lenguaje avanzados en nuestro propio hardware ha dejado de ser ciencia ficción para convertirse en una realidad accesible. Pero, ¿qué ocurre realmente bajo el capó? ¿Qué son GGUF, RAG o un motor de inferencia? Esta guía desglosa los pilares conceptuales de la IA autoalojada para que puedas comprender y dominar esta tecnología.
Tabla de contenidos [Mostrar]
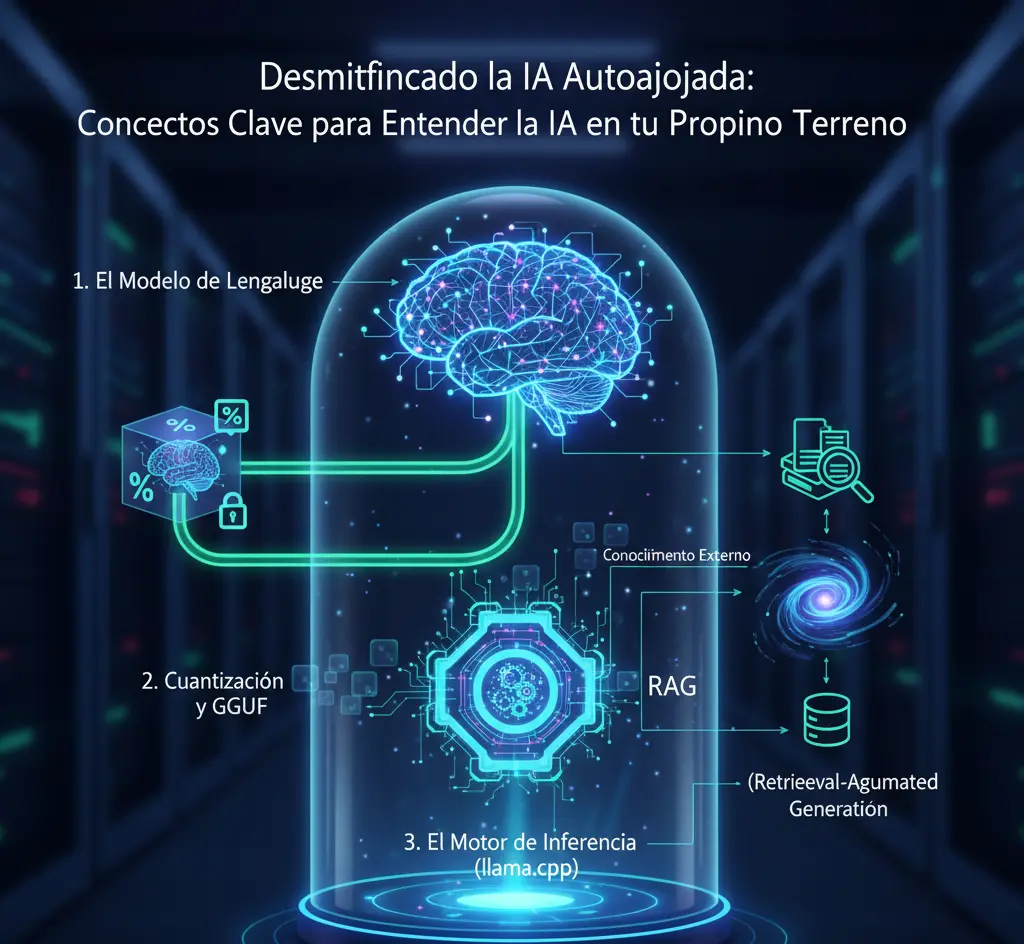
Todo comienza con el modelo. Piénsalo como un cerebro digital inmenso, entrenado para entender y generar lenguaje humano.
El principal obstáculo para ejecutar estos "cerebros" gigantes es su tamaño. Un modelo de 7 mil millones de parámetros en su formato original ( FP16 ) necesita unos 14 GB de VRAM, algo fuera del alcance de la mayoría. Aquí es donde entra en juego la cuantización.
llama.cpp , GGUF (GPT-Generated Unified Format) es un contenedor que empaqueta los pesos ya cuantizados del modelo en un único archivo. Su genialidad es que está diseñado para ser cargado y ejecutado de manera ultraeficiente tanto en la VRAM de la GPU como en la RAM del sistema para ser procesado por la CPU. Es el estándar de facto para la inferencia local.Tener un archivo GGUF no es suficiente; necesitas un programa que sepa cómo leerlo y usarlo para generar texto. Ese programa es el motor de inferencia.
llama.cpp . Este es el proyecto de software que impulsa casi todo el ecosistema de IA local. Es un motor de inferencia increíblemente optimizado, escrito en C++, capaz de ejecutar modelos GGUF aprovechando al máximo cualquier hardware disponible: GPUs de NVIDIA, AMD, Apple Silicon y CPUs. Herramientas como Ollama, LM Studio o Jan.ai son, en esencia, interfaces de usuario amigables que utilizan llama.cpp por debajo.Un LLM base solo conoce la información con la que fue entrenado. No sabe nada sobre tus documentos privados, tus correos o lo que pasó en el mundo ayer. RAG es la técnica que soluciona esto, dándole al modelo acceso a conocimiento externo en tiempo real.
En resumen, RAG es como darle al LLM un examen a libro abierto: no le pides que recuerde la respuesta, sino que la encuentre en los documentos que le proporcionas en el momento.
Entender estos cuatro conceptos clave te permite ver el ecosistema de la IA autoalojada no como una caja negra, sino como un sistema compuesto por piezas interconectadas:
llama.cpp a través de Ollama) para ejecutarlo (el motor que lo hace funcionar).Dominar estos fundamentos es el primer paso para pasar de ser un simple usuario de IA a convertirte en un creador capaz de construir soluciones privadas, personalizadas y verdaderamente potentes.